The Institutional Governance Question No One Owns Yet: 𝗠𝗮𝘆 𝗧𝗵𝗶𝘀 𝗔𝗰𝘁𝗶𝗼𝗻 𝗥𝘂𝗻 𝗔𝘁 𝗔𝗹𝗹?
If you skim my inbox and LinkedIn feed right now, the patterns are starting to rhyme.
Different authors. Different vendors. Different sectors.
But the same themes keep showing up:
- Context graphs & decision traces – “We need to remember why we decided, not just what happened.”
- Agentic AI – the question is shifting from “what can the model say?” to “what can this system actually do?”
- Runtime governance & IAM for agents – identity and policy finally move into the execution path instead of living only in PDFs and slide decks.
All of that matters. These are not hype topics. They’re real progress.
But in high-stakes environments – law, finance, healthcare, national security – there is still one question that is barely named, much less solved:
Even with perfect data, a beautiful context graph, and flawless reasoning…
𝗶𝘀 𝘁𝗵𝗶𝘀 𝘀𝗽𝗲𝗰𝗶𝗳𝗶𝗰 𝗮𝗰𝘁𝗼𝗿 𝗮𝗹𝗹𝗼𝘄𝗲𝗱 𝘁𝗼 𝗿𝘂𝗻 𝘁𝗵𝗶𝘀 𝘀𝗽𝗲𝗰𝗶𝗳𝗶𝗰 𝗮𝗰𝘁𝗶𝗼𝗻, 𝗳𝗼𝗿 𝘁𝗵𝗶𝘀 𝗰𝗹𝗶𝗲𝗻𝘁, 𝗿𝗶𝗴𝗵𝘁 𝗻𝗼𝘄?
That’s not a data question.
It’s not a model question.
It’s an
authority question.
And it sits in a different layer than most of what we’re arguing about today.
The Layers Everyone Is Now Talking About
Let’s name the pieces that are getting serious attention, because they’re important – they’re just not sufficient.
1. Context Graphs → Remembering How Decisions Get Made
Context graphs are about giving agents memory and structure:
- They connect people, systems, and prior decisions.
- They help an agent say: “In similar cases, here’s how we’ve handled this before.”
Done well, they help systems remember how decisions were made, not just the final outcomes. That’s a big leap from stateless prompts.
2. Decision Traces → Making Judgment Auditable
Decision traces are the other half of that story:
- Who decided what?
- Under which constraints?
- With what precedent?
- What exceptions and overrides were involved?
Done well, decision traces make judgment auditable. Boards, regulators, and internal risk teams can see how a decision was reached – not just that it appeared in a log.
3. Agentic AI → From Answers to Actions
Agentic AI is where the stakes go up:
- Not just “answer this question.”
- But “plan, call tools, interact with systems, and carry this through.”
It turns “insight” into sequences of steps that actually move money, send communications, change records, file requests, submit orders.
That’s where the gap between reasoning and authority really starts to matter.
4. IAM for Agents → Who May Reach What
Identity & Access Management for agents is the natural response:
- Give non-human identities (agents, workflows, services) their own credentials.
- Control which APIs, databases, and services they can reach.
- Apply context (environment, device, network, workload) to tighten access.
IAM for agents answers:
“Which non-human identities may reach which systems and data?”
That’s essential – but still about access, not execution.
5. Runtime Monitoring & “AI Sec Meshes” → What Just Happened?
Finally, there’s the observability layer:
- Capture what models and agents actually did.
- Detect drift, misuse, prompt injection, data leakage.
- Feed that back into controls, audits, and red-teaming.
This tells you after the fact what the system did, so you can tighten controls and respond.
All of this can be brilliant and correct.
And you can still be completely out of authority.
Correct, Compliant… and Still Out of Bounds
Here’s the uncomfortable reality in regulated environments:
You can have:
- Perfect retrieval.
- A rich context graph.
- Beautiful decision traces.
- An agent that plans and acts exactly as designed.
- IAM and runtime meshes operating exactly as specified.
…and still end up with an action that should never have been allowed to execute.
Why?
Because none of those layers answer the one question boards, GCs, and CISOs actually get judged on:
“Given this actor, this context, and this authority — may this specific action execute right now: allow / refuse / supervised override?”
Everything else is inputs, reasoning, and visibility.
That question is about
who is allowed to commit the irreversible step.
- In law: file a motion, send a communication to court or counterparty, bind a client.
- In finance: move funds, approve a trade, sign a binding contract.
- In healthcare: finalize orders, sign a prescription, submit to a payer.
- In cyber / OT: push a configuration, trigger a shutdown, execute a live playbook.
The harm doesn’t come from a hallucinated sentence in a draft.
It comes from the
action that leaves the building under your name.
That’s a different control surface.
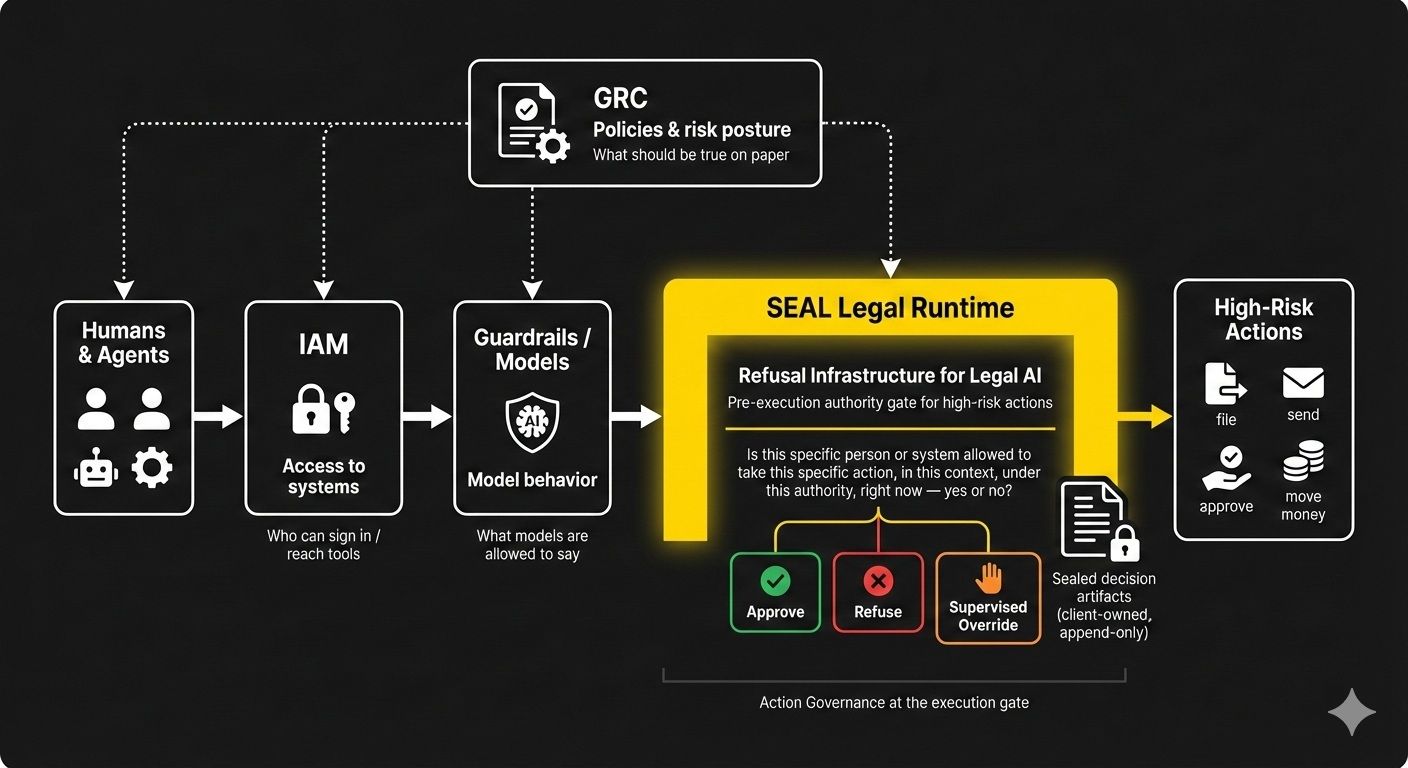
The Missing Layer: Pre-Execution Authority Gate
Call it what you like – an authority gate, a refusal layer, an execution-time gate.
Structurally, it does one thing:
At the action boundary, it decides:
allow / refuse / supervised override – and leaves behind evidence of that decision.
A real pre-execution authority gate has three defining properties:
1. It Is Pre-Execution
- It sits in front of high-risk actions in wired workflows.
- If the gate doesn’t return “allow,” the action does not run.
- There is no silent “alternate path” for that action in that workflow.
If the workflow can still execute without a verdict from the gate, it’s not an authority gate. It’s just monitoring.
2. It Is Authority-Aware, Not Model-Aware
It doesn’t care how clever the model was.
It cares about:
- 𝗪𝗵𝗼 is acting? (human, agent, service account)
- 𝗪𝗵𝗲𝗿𝗲 are they acting? (practice area, business line, jurisdiction)
- 𝗪𝗵𝗮𝘁 are they trying to do? (file, send, approve, move, commit)
- 𝗛𝗼𝘄 𝗳𝗮𝘀𝘁 / 𝗵𝗼𝘄 𝗲𝘅𝗽𝗼𝘀𝗲𝗱 is it? (standard, expedited, emergency)
- 𝗨𝗻𝗱𝗲𝗿 𝘄𝗵𝗶𝗰𝗵 𝗮𝘂𝘁𝗵𝗼𝗿𝗶𝘁𝘆? (client consent, internal policy, license, role)
Think of it less as a “safety filter” and more as a live authority check.
3. It Produces Evidence-Grade Artifacts
Every decision – especially refusals and supervised overrides – leaves behind a sealed record:
- Who attempted the action.
- What they tried to do.
- Which rules or policies fired.
- The verdict (allow / refuse / escalate).
- A human-readable reason code.
Not full prompts, not client matter content – just enough to support:
- Internal review and supervision.
- Regulator or insurer questions.
- Later litigation and professional responsibility inquiries.
If you can’t show why an action was allowed to execute, at the moment it executed, you are effectively outsourcing judgment to a black box – even if all the other layers are beautifully instrumented.
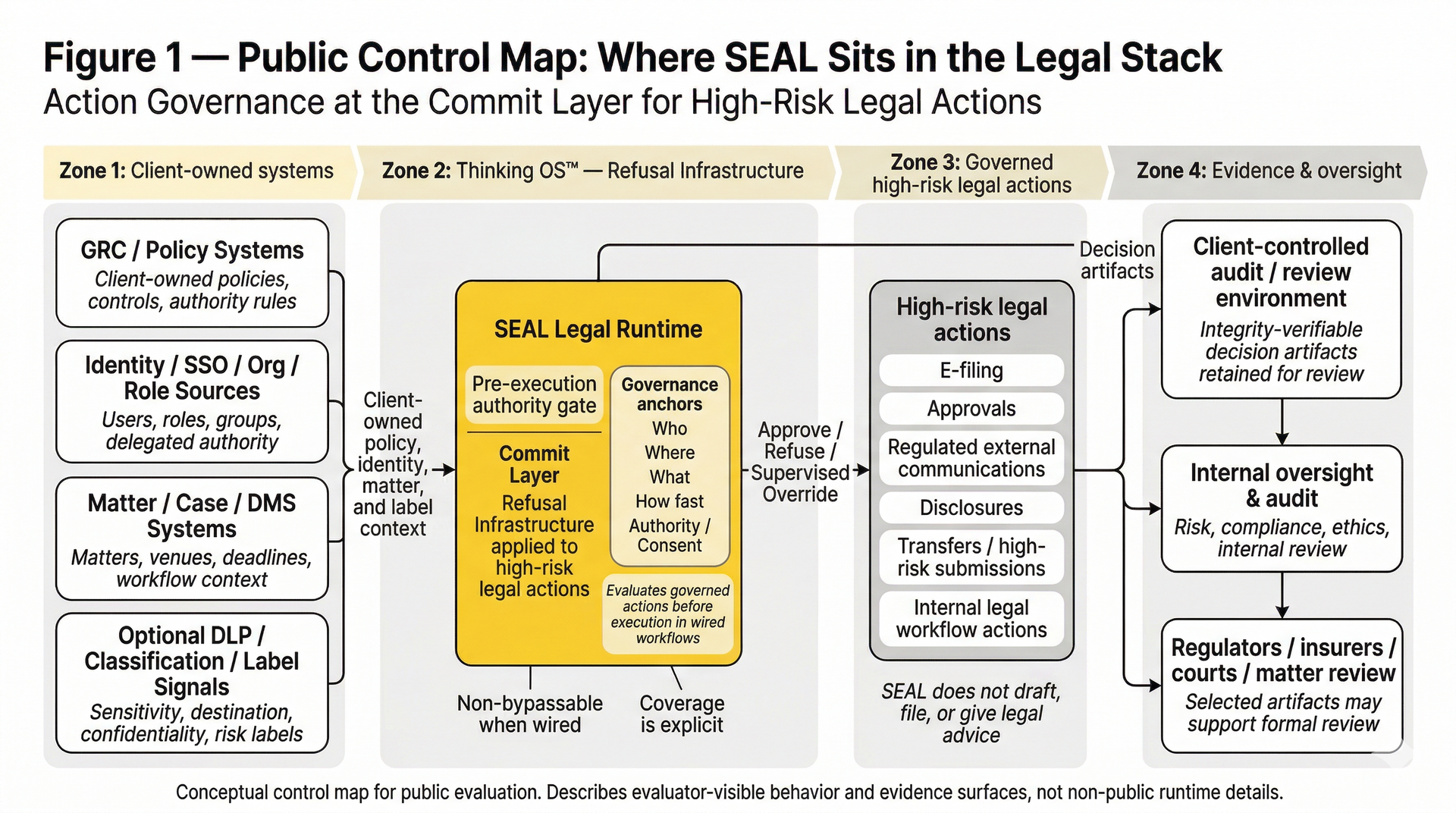
How This Sits Above the Other Layers (Not Instead of Them)
So where does this pre-execution authority gate / refusal layer fit?
It doesn’t replace IAM, context graphs, decision traces, or runtime meshes.
It sits on top of them
and uses them as inputs.
- Context graphs and decision traces: help the organization and the agents reason better and explain themselves. The pre-execution authority gate doesn’t build them; it relies on your policies and governance to define what counts as “in bounds.”
- Agentic AI: does the planning, tool calling, and orchestration. The pre-execution authority gate doesn’t tell it how to think; it decides whether the proposed action is allowed to run at all.
- IAM for agents: ensures only the right non-human identities can even reach the tools and systems involved. The pre-execution authority gate assumes IAM is working and then answers: “even so, is this specific action authorized right now?”
- Runtime monitoring / AI sec meshes: watch what happened across models and agents. The pre-execution authority gate reduces what they have to explain by refusing actions that never should have been launched in the first place.
In other words:
- IAM answers who may connect.
- Context graphs & decision traces answer how we reason.
- Agentic AI answers what we can do.
- Monitoring answers what happened.
- An pre-execution authority gate answers what is allowed to execute – and proves it.
That last bit – and proves it – is what boards, regulators, and malpractice insurers keep asking for, often in different language.
The Question Every Stack Needs to Be Able to Answer
As AI moves from “assistant” to “actor,” the real risk isn’t just that systems make bad suggestions.
It’s that they take irreversible actions without a clear, provable authority check.
So here’s the simple, brutal test I keep coming back to:
In your stack today, for each high-risk action (file / send / approve / move / commit):
Who or what actually owns the final “may this run at all?” decision?
And can you prove it, action by action, six months from now?
If the honest answer is:
- “We assume IAM plus logging is enough,” or
- “We hope the agent’s guardrails will catch it,” or
- “We can reconstruct it later from dashboards and traces,”
…then you’ve just found your missing layer.
That’s the space we're working in with SEAL Legal Runtime in law: a pre-execution, refusal-first authority gate in front of high-risk legal actions, with sealed, client-owned artifacts for every yes / no / supervised override.
Different domain, same structural question.
Because at some point, for every regulated workflow that can now run at machine speed, someone around the table needs to be able to look a board, a regulator, or a court in the eye and answer:
“Yes, we know who was allowed to do what, under which authority, and here is the record that proves it.”
Until that layer exists, context graphs, decision traces, agentic AI, IAM for agents, and runtime meshes will all keep getting better.
And the most important question in Institutional Governance will still be mostly unanswered.









