Guardrails vs. Pre-Execution Governance: What Regulators Actually Need to Ask
Short version:
- Guardrails control what an AI system is allowed to say.
- A pre-execution governance runtime controls what an AI system is allowed to do in the real world.
If you supervise firms that use AI to file, approve, or move things, you need both. But only one of them gives you decisions you can audit.
For the full spec and copy-pasteable clauses, see:
“Control Objectives & Evaluation Criteria (2026 v1.0)”
1. What “Guardrails” Actually Do (in Plain Language)
When vendors say they have “AI guardrails,” they usually mean:
- The model is restricted in what it can say or generate (no hate speech, no PII, no legal advice, etc.).
- Prompts and outputs may be filtered or modified before the user sees them.
- The system might refuse certain questions (“I can’t help with that”).
Guardrails are about content and behavior at the model layer:
“Given this prompt, what responses are allowed or blocked?”
They are useful. They reduce obviously bad outputs. But guardrails:
- Do not decide whether a filing should be submitted.
- Do not control whether a payment actually moves.
- Do not produce the kind of sealed, reproducible evidence regulators and courts need when something goes wrong.
Guardrails are necessary but not sufficient for supervised entities using AI in high-risk workflows.
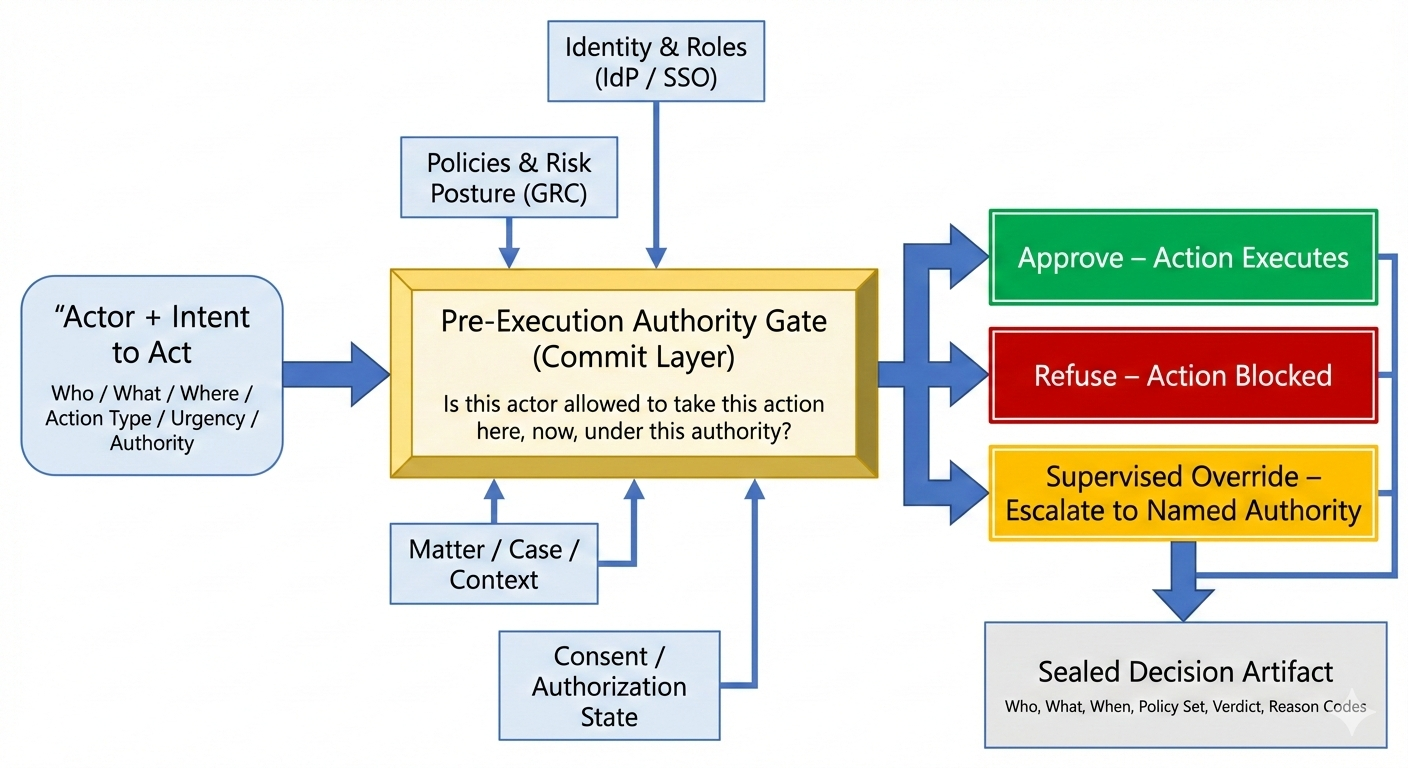
2. What a Pre-Execution Governance Runtime Is
A pre-execution governance runtime is different.
It is a gate in front of high-risk actions (file, submit, approve, move money, change records) that decides:
“Is this specific person or system allowed to take this specific action, in this matter, under this authority, right now?”
In plain language:
- It sits between AI tools / applications and the systems that actually act (courts, regulators, payment rails, core systems).
- It evaluates who is acting, on what, under which rules, and at what urgency.
- It returns one of three outcomes for each request:
- ✅ Approve – action may proceed.
- ❌ Refuse – action is blocked.
- 🟧 Supervised Override – action may proceed only if a named human decision-maker accepts responsibility.
Crucially, it produces a sealed artifact for every decision:
- Tamper-evident
- Tenant-controlled
- Designed so regulators, auditors, and insurers can see what the gate decided and why, without exposing full client content or proprietary logic.
For a detailed definition, see:
“Control Objectives & Evaluation Criteria (2026 v1.0)”
3. Why This Distinction Matters for Regulators
From a supervisory perspective:
- Guardrails are about model safety
→ “What can this AI say?” - Pre-execution governance is about institutional control
→ “What can this AI (or human using AI) actually do in our legal and regulated systems?”
Without a pre-execution runtime:
- A model can behave “safely” and still submit the wrong document to the wrong forum.
- There may be no reliable record of who approved what, under which rules.
- After an incident, firms are forced into forensic reconstruction from logs and emails.
With a sealed pre-execution runtime:
- You get a clear point of responsibility: this gate approved/refused/required override at this time under these rules.
- You can sample artifacts across workflows and time, instead of reverse-engineering incidents.
- You can write concrete requirements into rules, guidance, and exam manuals.
4. Mini-Checklist: What Regulators Should Ask
When a supervised entity says “we use AI for X,” you can separate guardrails from governance with a few questions.
A. Guardrails (Good, But Not Enough)
These are reasonable questions, but they’re about the model:
- What guardrails or safety policies apply to your AI models?
- How do you prevent obviously harmful or prohibited outputs?
- How do you monitor and update those guardrails over time?
You’ll hear about prompt filters, content filters, red-team tests. Useful, but not the whole story.
B. Pre-Execution Governance (Non-Negotiable for High-Risk AI)
For workflows where AI can submit, approve, or move things, you should be asking:
1.Execution Gate
- Do you front high-risk AI workflows with a pre-execution governance runtime that evaluates actions before they are executed?
2. Fail-Closed Behavior
- What happens when policy, identity, or context is ambiguous or missing?
- Does the system fail closed (refuse), or does it “do its best”?
3. Non-Bypassability
- Can high-risk actions be executed without passing through this runtime?
- If yes, under what documented contingency procedures?
4.Evidence & Artifacts
- Do you generate sealed, tamper-evident artifacts for every approve, refuse, and supervised override decision?
- Who controls those artifacts, and how long are they retained?
5. Policy & Identity Sources
- Does the runtime rely on entity-owned policy, identity, and matter data (GRC, IdP, case/matter systems), or on vendor-specific configuration?
6. Override Accountability
- When an override is used, is a named human decision-maker recorded in the artifact?
- How are overrides reviewed internally?
For a more detailed supervisory checklist, see the
“Integration Requirements & Evaluation Checklist” section in:
“Control Objectives & Evaluation Criteria (2026 v1.0)”
5. How to Use This in Practice
You can start small:
- In guidance or discussion papers, introduce the distinction:
- “Guardrails govern model outputs; pre-execution runtimes govern real-world actions.”
- In exams and on-sites, add 3–5 concrete questions from the mini-checklist above.
- In future rules or expectations, point firms to:
- Sealed AI Governance Runtime: Reference Architecture & Requirements for 2026
as an example of the behaviors and guarantees you expect from a pre-execution governance layer.
You don’t have to mandate a specific vendor or implementation.
You can simply say:
“If you use AI to submit filings, approve decisions, or move assets, we expect a pre-execution governance runtime that:
- fails closed,
- is non-bypassable,
- and emits sealed, tenant-controlled artifacts for every decision.”
Guardrails keep models in bounds.
Pre-execution governance keeps institutions in control.
Your questions should reflect that difference.









