Everyone’s Optimizing AI Output. Almost No One Governs What Can Execute.
Legal AI has crossed a threshold. It can write, summarize, extract, and reason faster than most teams can verify.
But under the surface, the real fracture isn’t about accuracy. It’s about actions that were never structurally authorized to run.
Here’s the gap most experts and teams still haven’t named.
1. Everyone’s Still Optimizing the Response
Most legal AI conversations still orbit the same questions:
- How fast is it?
- How accurate is the draft?
- Can it cite?
- Does it save time?
All important. None of them answer the one question that actually shows up in court or with insurers:
“Given this actor, this matter, and this authority — was this action ever allowed to execute at all?”
A system can be 100% right on analysis and still not be allowed to act.
Until you have a structural way to say no at the action boundary, performance is not proof of governance.
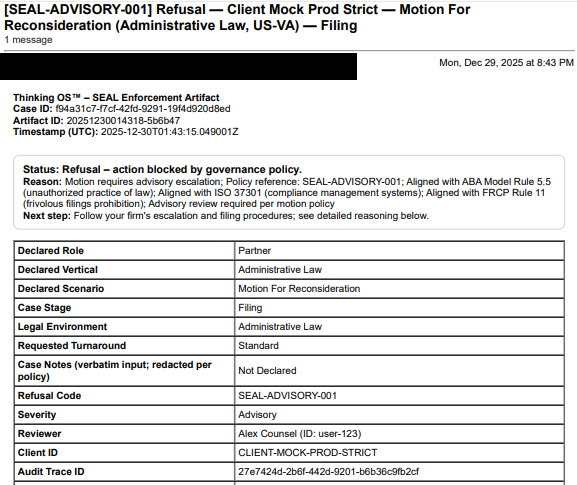
2. The “Governance Layer” Is Mostly After the Fact
What most teams call “governance” today is post-execution control:
- Filters and guardrails
- RAG pipelines
- Usage policies and playbooks
- Human-in-the-loop review
- Logs and dashboards
All necessary. All downstream.
By the time those kick in, the risky part already happened:
- The AI-drafted email was sent.
- The filing left the building.
- The approval hit the system of record.
That isn’t governance. That’s forensics.
Real governance needs a pre-execution authority gate in front of high-risk steps — a layer that can say:
“For this specific person or system, in this matter, under this authority, may this file / send / approve action proceed right now: allow / refuse / escalate?”
If no one is answering that question in real time, you don’t have runtime governance. You have hopes.
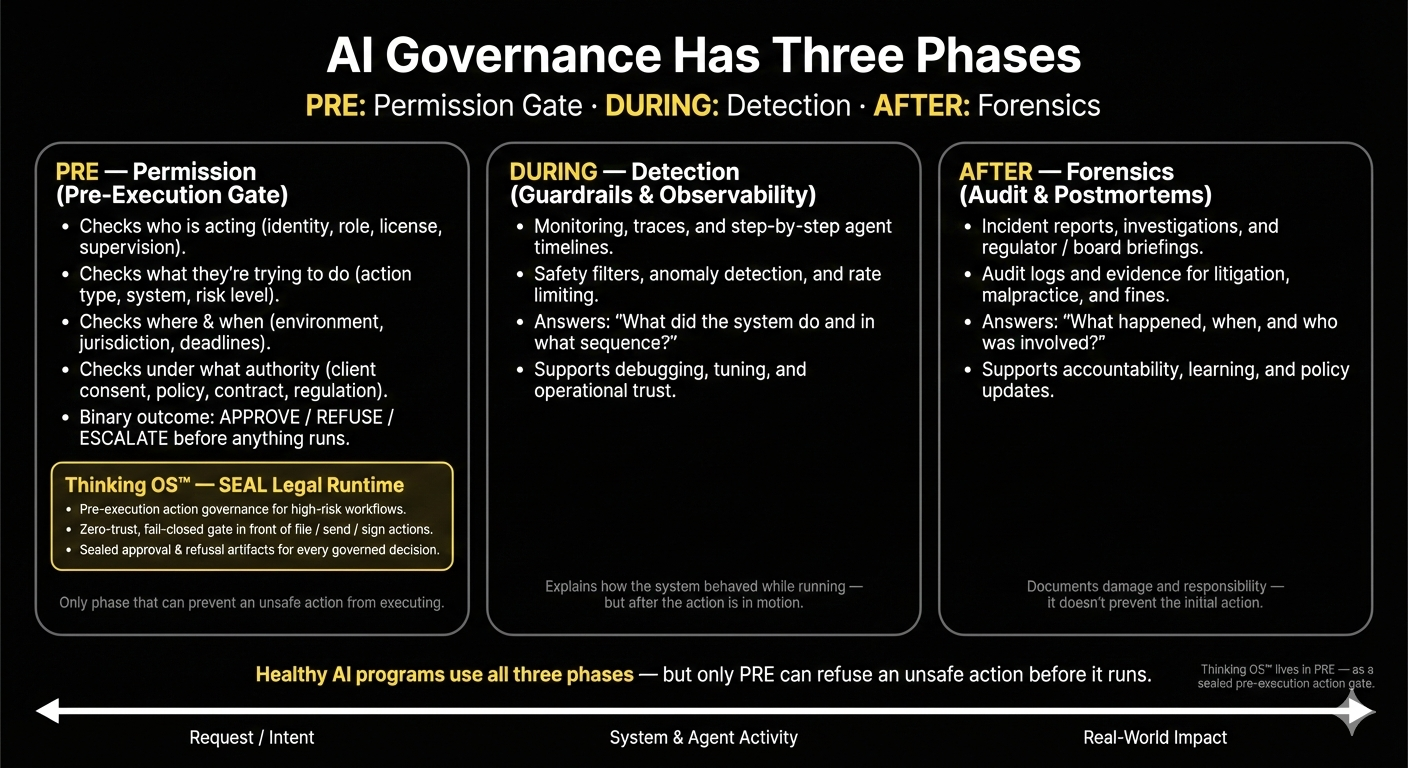
3. Judgment Is Being Misdefined
In most AI programs, “judgment” gets treated as:
- Picking the best draft,
- validating citations, or
- asking “does this look right?” after the system runs.
That’s quality control, not judgment.
In regulated environments, judgment is structural:
Judgment is the condition under which an action is permitted to exist in the real world.
It’s not “do we like this answer?”
It’s
“is anyone explicitly authorized to let this action happen at all?”
That’s the discipline we call Action Governance:
- Who may act
- On what
- Under whose authority
- In this context
- At this moment
Enforced before a filing, communication, or approval leaves the firm.
Without that pre-execution authority gate, you can have beautiful context graphs, decision traces, and model monitoring — and still no structural way to stop the wrong thing from happening under your seal.
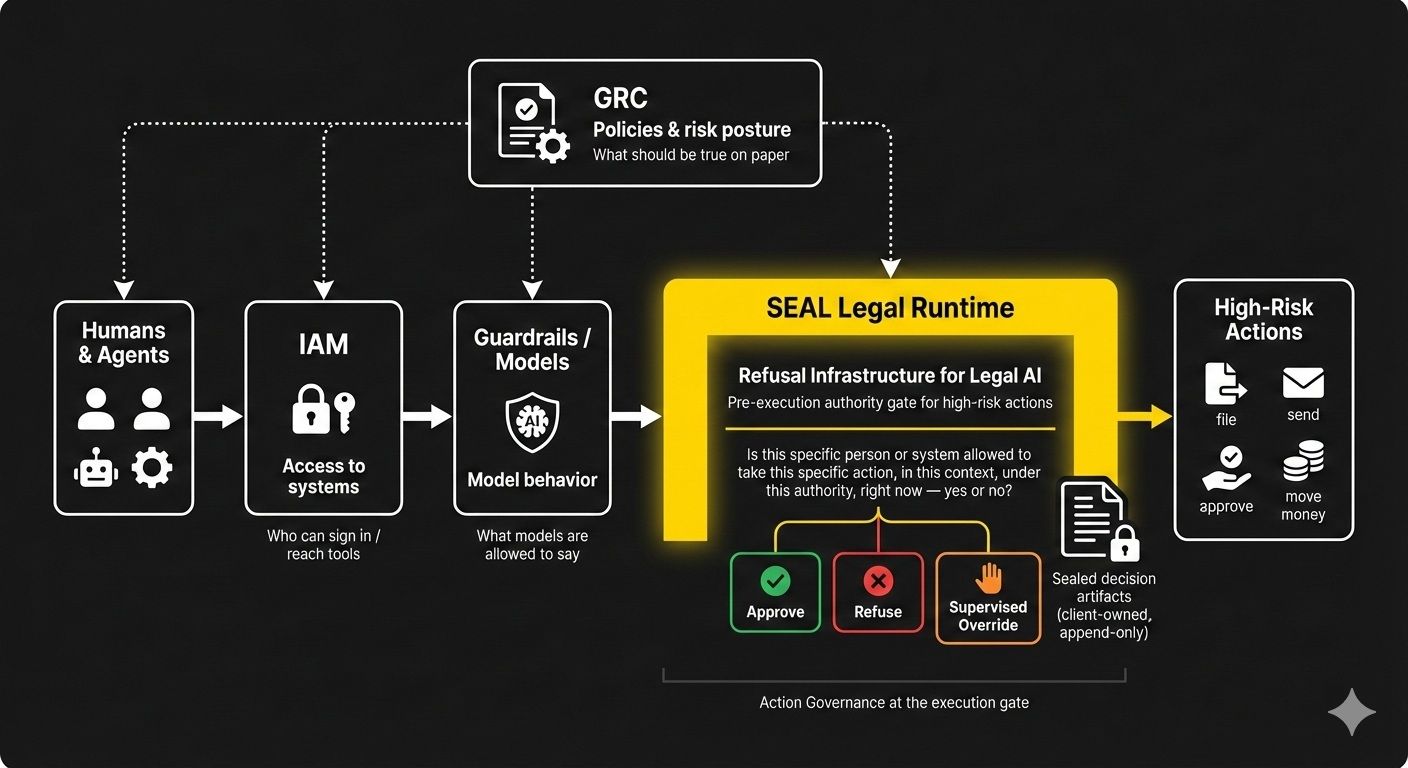
Final Thoughts
Legal AI isn’t drifting because the models are bad.
It’s drifting because we let systems act on our behalf without a non-bypassable answer to a simple question:
“Is this specific action allowed to execute, right now?”
The real edge over the next 12–24 months won’t be better prompting or prettier copilots.
It will be refusal infrastructure at the execution gate — action governance that can block, not just observe, what your AI stack is allowed to do.
Until that exists in your stack, the risk isn’t just what AI says.
It’s what you’ve given it the power to do.









