The Law Can’t Govern AI — Until Judgment Becomes Admissible
Why Pre-Execution Judgment Is the New Foundation for Legal-Grade AI
Ask any regulator, GC, or judge a simple question:
“What governs the system before it moves?”
Most don’t get a clear answer.
Most enterprises can’t prove it.
Most AI vendors never designed for it.
Policy is everywhere.
Admissible judgment — proof of who allowed what to execute,
under which authority— is almost nowhere.
Governance Isn’t What You Write. It’s What You Refuse to Execute.
Regulators are racing to issue rules.
Enterprises are stockpiling AI playbooks.
Vendors are rushing to bolt on “governance layers” so procurement can say yes.
None of that matters if your stack can’t do three things at the execution edge:
- Refuse out-of-policy actions before they run.
- Record that decision in a structured, tamper-evident way.
- Prove it later to courts, regulators, and insurers without exposing client content.
That is not detection.
That is
permission.
Right now, most legal and compliance programs are still trying to govern systems that can:
- form logic,
- trigger actions, and
- alter records
before any structural authority check fires.
Unsafe Logic Isn’t Just a Bug. It’s Evidence of a Missing Execution Gate.
Ask your AI or workflow vendor one question:
“Where is your pre-execution authority gate — the thing that can say no?”
If they point to filters, red-teaming, RAG pipelines, or dashboards, they’re answering a different question:
- Those are post-output controls.
- They observe or correct what already happened.
- They do not govern which actions are allowed to execute in the first place.
Legal systems don’t trust “we fixed it later.”
They trust
structural disqualification — clear rules about what was never allowed to happen at all.
“Explainability” Was Never Enough
Most AI policies still fixate on:
- “Explain how the model decided.”
- “Document behavior.”
- “Prove it followed the rules.”
That’s retroactive comfort, not structural integrity.
In court, the key question is almost never:
“Can you narrate what the model did?”
It’s closer to:
“Who had the authority to let this action proceed, on this matter, under this law — and what evidence shows they exercised that authority?”
That’s not a slide about model weights.
That’s a
license boundary at the action layer.
The Missing Legal Layer: Licensed Action Governance
In regulated work, cognition is cheap; authority is expensive.
The real risk is not that an AI system had a bad idea.
It’s that a bad or out-of-scope idea
made it into a filing, a payment, a record, or a client communication without licensed judgment in the loop.
So the relevant question isn’t:
“Was the model well-aligned?”
It’s:
“Did this action have a licensed decision behind it — and can we show that in evidence?”
That’s what Action Governance provides:
- For every high-risk step (file, send, approve, move money…),
- You can ask, structurally:
“Given this actor, this matter, this authority and consent —
may this action run at all: allow / refuse / supervise?”
And you keep the answer.
Refusal Infrastructure: Making Judgment Admissible
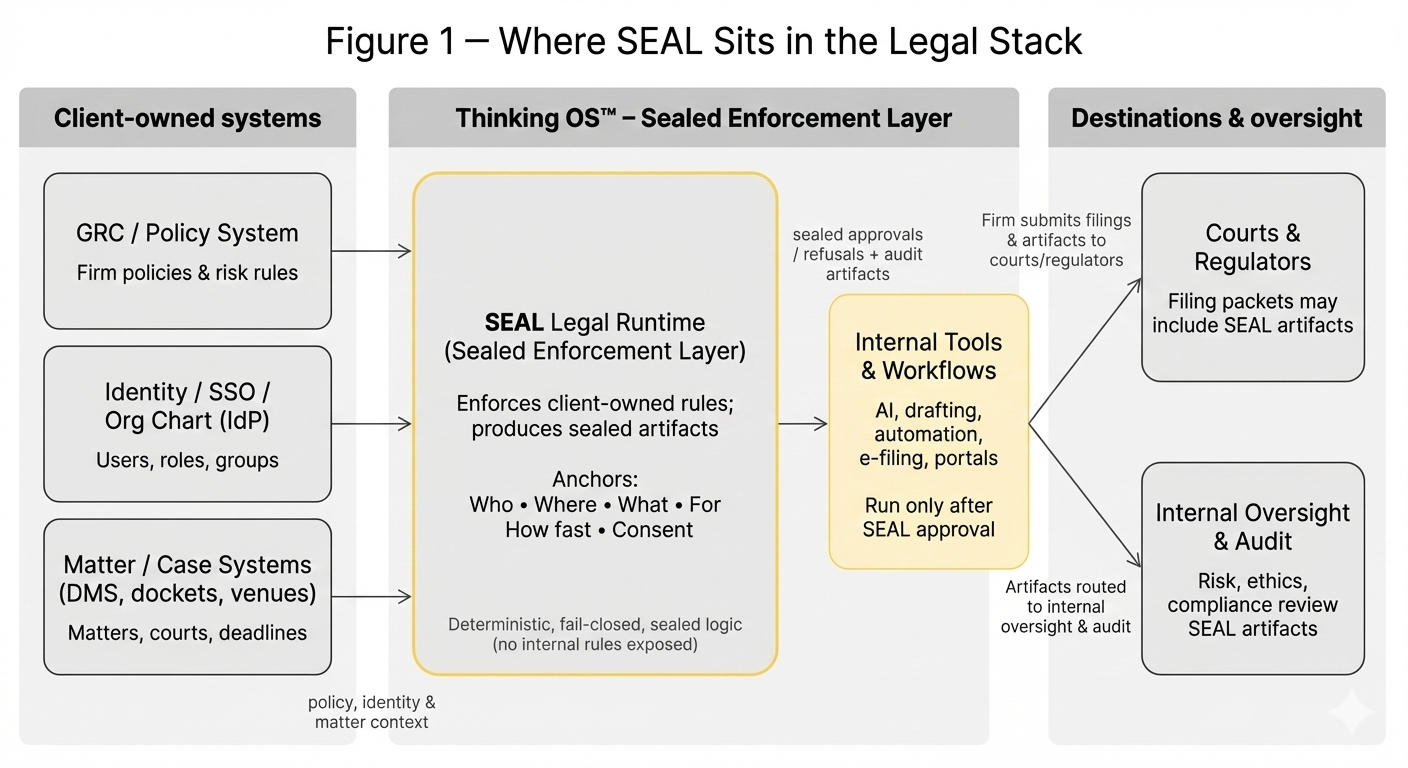
This is where Refusal Infrastructure for Legal AI comes in.
Instead of trying to govern what models think, it governs what your systems are allowed to execute, and produces evidence of that judgment.
In a SEAL-governed workflow:
- Your systems send a small, structured
intent to act payload to the SEAL Legal Runtime
– who is acting,
– on which matter/context,
– what they’re attempting (motion/action type),
– urgency,
– and a reference to the authority/consent state in your own systems. - SEAL evaluates that intent against client-owned identity, matter, and policy systems.
- It returns one of three outcomes:
- Approve – the action may proceed.
- Refuse – the action is blocked.
- Supervised override – routed to named authority under your policy.
4. Every decision generates a sealed artifact written to client-owned audit storage:
- who tried to act,
- what was evaluated,
- what policy anchors applied,
- the outcome, and
- when it occurred.
No drafting.
No filing.
No “assistant” behavior.
Just governed, sealed judgment at the execution gate.
Why This Matters for Courts and Regulators
Once AI and automation sit inside legal workflows, three questions dominate:
- Who allowed this action to proceed?
- Under what authority and policy?
- Where is the evidence you enforced that in real time?
Without a pre-execution gate and sealed artifacts, most organizations answer with:
- screenshots,
- logging snippets, or
- vendor attestations.
That’s not “governance.”
That’s storytelling.
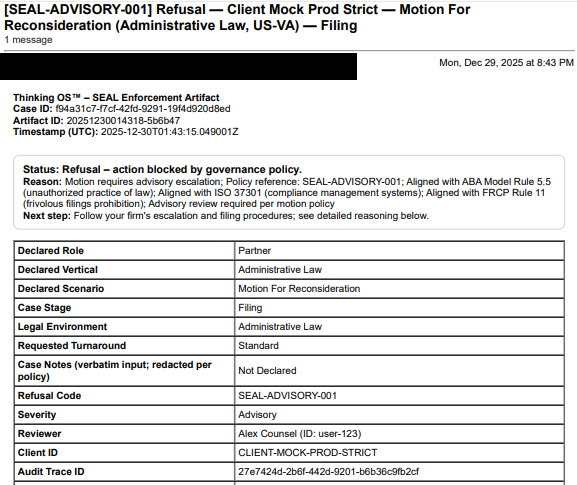
With refusal infrastructure in place, the answer becomes:
“Here is the sealed decision artifact showing that, at the time of execution, this action was evaluated against our policies and authorities. It was [approved / refused / overridden] under this regime.”
That’s the difference between “we tried to be careful” and admissible proof of judgment.
What This Means for Legal and Risk Leaders
If you’re a GC, CISO, managing partner, or agency head, the next hard case won’t be about a single hallucinated paragraph.
It will sound more like:
“Your system executed an action outside delegated authority.
Show us the layer that was supposed to stop it — and the evidence that it did, or did not, fire.”
Red teams won’t answer that.
Model cards won’t answer that.
Policy PDFs won’t answer that.
Only a pre-execution authority gate with sealed, client-owned decision artifacts can.
You don’t need another model that explains itself.
You need infrastructure that can
prove which actions earned the right to execute in your name.
Thinking OS™ and SEAL Legal Runtime
Thinking OS™ is not another legal AI tool.
It provides Refusal Infrastructure for Legal AI:
- Discipline: Action Governance
- Layer: a sealed governance gate in front of high-risk legal actions
- Product: SEAL Legal Runtime — a sealed judgment perimeter for law firms, legal departments, and legal-tech vendors.
It doesn’t replace lawyers or your existing tools.
It sits in front of your “file / send / approve / move” buttons and:
- evaluates each governed request against your identity, matter, and policy systems,
- returns approve / refuse / supervised override, and
- emits a tamper-evident decision artifact for every outcome.
That’s how judgment becomes something the law can actually see, test, and rely on.
Admissibility Is the Next AI Frontier
The future of legal AI will not be decided by:
- which model is smartest, or
- which assistant writes the fastest draft.
It will be decided by one quieter question:
“When this action was taken, can you prove who allowed it, under what authority, and why?”
Until you can answer that with
sealed, structural evidence, you don’t have AI governance.
You have AI optimism.
Refusal Infrastructure for Legal AI — and SEAL Legal Runtime in particular — exists to close that gap:
- Governance as a gate, not a slide deck.
- Judgment as an artifact, not a hope.
That’s what makes AI something the law can finally govern.









